










Clarifying the Data Question
Jeff Leek and Roger Peng, statisticians at Bloomberg School of Public Health at Johns Hopkins University, have described a structure to understand data problems (Science, 21 March 2015). The paper is concise and clear, well worth the read.
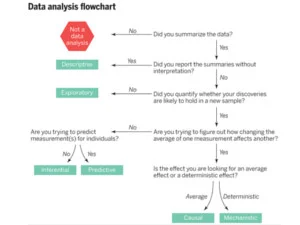
Leek and Peng seek to clarify common confusions among aims of data analysis. They summarize their view in a flowchart, shown here.

Confusion in aims of a data analysis leads to misinterpretation of results, usually when an analysis at a lower level is interpreted at a higher level. It seems that analysts and clients are often reaching for a deep level in the flowchart—e.g. reaching for evidence that changing process variables will lead to changes in outcome performance—when the analysis does not support that reach.
I know I could have used something like Leek and Peng’s flowchart in a recent project. I had to explain to a client that the best we could do was an exploratory analysis rather than a classic inferential study. As usual, a picture would have helped.
The client had records measuring ecological integrity of transects within sites. Ecologists had applied a range of management interventions to the sites, all aimed at increasing ecological integrity over time, as measured by indices like the total number of native species observed. The client reasoned that they had a lot of data and there must be a way to show that certain interventions had the desired effect of increasing ecological integrity.
On investigation, given the number of interventions and the relatively low number of transects with multiple observations over time, we did not have enough data to do more than summarize relationships and, working with an ecologist colleague, describe connections between patterns in the data and plausible ecological mechanisms.
In this case, we were dealing with happenstance data rather than a randomized experimental design. If the interventions had been applied using appropriate randomization, then we would have been able to take a further step to analyze the data in an effort to draw inferences about average impact of interventions. Of course, given the variation in the outcome measures, a designed study might not have had sufficient power to distinguish effects but we would have been on firm ground to make the effort.
Leek and Peng do not insist on randomized experimental designs to support the move from exploratory analysis to inferential analysis. If one has “enough” data, we can divide the data into training, test, and validation sets to both build a model and estimate how the model might perform with new samples. This approach depends on computing power not available to Fisher when he invented the method of designed experimentation.

